作者:Chenwei Lin,Hanjia Lyu,Xian Xu,Jiebo Luo 发布时间:2024-06-23 18:10:46 来源:复旦发展研究院+收藏本文

近年来,视觉语言大模型(Large Vision Language Models, LVLMs)在多模态任务中,尤其在图像识别、文档解析和OCR处理等领域展现出卓越的性能。然而,LVLMs在保险领域的应用潜力尚未得到有效探索。近日,在复旦大学许闲教授团队与罗切斯特大学罗杰波教授团队合作的一项最新工作中,他们系统梳理了保险领域的多模态任务,并提出了首个为保险领域量身定制的LVLMs综合基准测试数据集——INS-MMBench。这个新的数据集涵盖2200道选择题、12个元任务和22个子项目。通过此基准测试,这项新工作不仅验证了多种LVLMs在保险领域任务中的有效性,还对其性能进行了深入分析,旨在推动LVLMs在保险行业的应用,并激发跨学科的发展。
Chenwei Lin, Fudan University
Hanjia Lyu, University of Rochester
Xian Xu, Fudan University
Jiebo Luo, University of Rochester
Large Vision-Language Models (LVLMs) have demonstrated outstanding performance in various general multimodal applications such as image recognition and visual reasoning, and have also shown promising potential in specialized domains. However, the application potential of LVLMs in the insurance domain—characterized by rich application scenarios and abundant multimodal data—has not been effectively explored. There is no systematic review of multimodal tasks in the insurance domain, nor a benchmark specifically designed to evaluate the capabilities of LVLMs in insurance. This gap hinders the development of LVLMs within the insurance domain. In this paper, we systematically review and distill multimodal tasks for four representative types of insurance: auto insurance, property insurance, health insurance, and agricultural insurance. We propose INS-MMBench, the first comprehensive LVLMs benchmark tailored for the insurance domain. INS-MMBench comprises a total of 2.2K thoroughly designed multiple-choice questions, covering 12 meta-tasks and 22 fundamental tasks. Furthermore, we evaluate multiple representative LVLMs, including closed-source models such as GPT-4o and open-source models like BLIP-2. This evaluation not only validates the effectiveness of our benchmark but also provides an in-depth performance analysis of current LVLMs on various multimodal tasks in the insurance domain. We hope that INS-MMBench will facilitate the further application of LVLMs in the insurance domain and inspire interdisciplinary development.
01
INS-MMBench: 保险领域首个LVLMs综合基准测试数据集
INS-MMBench是首个针对保险领域的综合性 LVLMs 基准,共包含2200道视觉多选题(multi-choice visual questions),涵盖12个元任务(meta-tasks)和22个基本任务(fundamental tasks)。
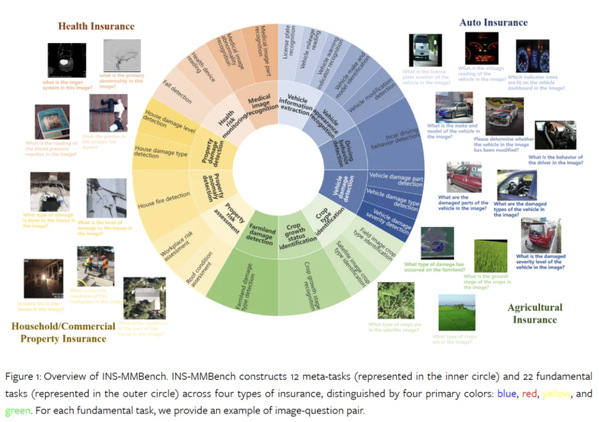
INS-MMBench涵盖了四个具有代表性的保险类型:汽车保险、财产保险、健康保险和农业保险,以及风险承保、风险监控和索赔处理等关键保险阶段。
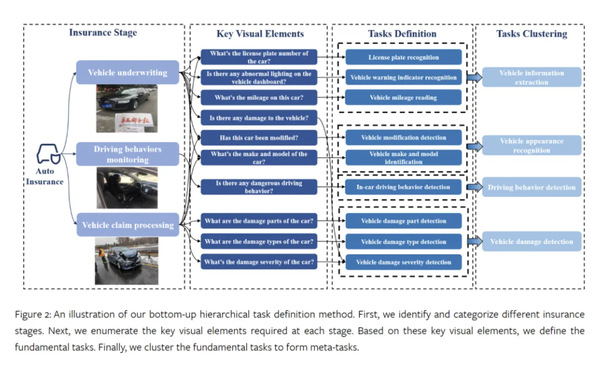
02
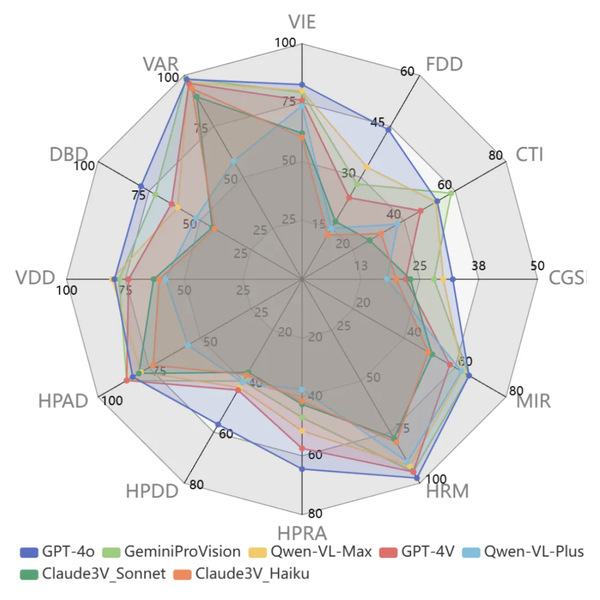
团队利用INS-MMBench对10个LVLM进行了深入评估,包括7个闭源LVLM:GPT-4o、GPT-4V、GeminiProVision、QwenVLPlus、QwenVLMax、Claude3V_Sonnet和Claude3V_Haiku,以及3个开源LVLM,包括LLaVA、BLIP-2和Qwen-VL-Chat。
评估结果显示,GPT-4o在INS-MMBench评估中以72.91的高分成为性能表现最佳的LVLM。
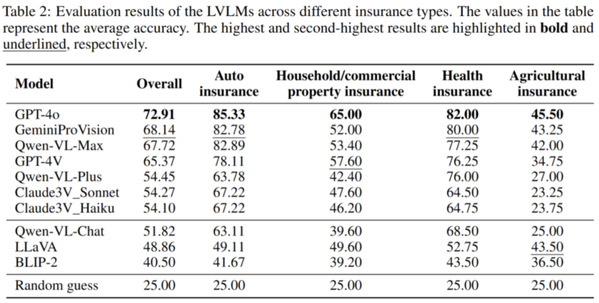
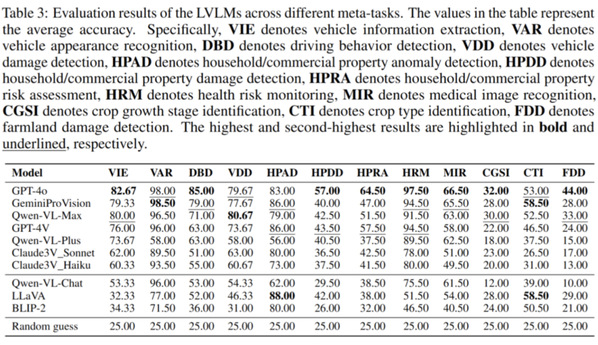
此外,团队观察评估结果发现,LVLMs在不同类型的保险和不同元任务中均显示出显著的性能差异,而开源和闭源LVLMs之间的性能差距正在缩小。
报告下载链接及二维码
https://arxiv.org/abs/2406.09105


CopyRight©2007 复旦发展研究院版权所有 备案号/经营许可号:沪ICP备05006147号
地址:上海市邯郸路220号智库楼 邮编:200433 电话:86-21-55670203 传真:86-21-55670203
电子邮箱:fdifudan@fudan.edu.cn
