作者:张傲 于玥 栗子宜 发布时间:2026-05-01 00:52:24 来源:复旦中美友好互信合作计划+收藏本文
引言
自2026年初以来,美国头部人工智能实验室围绕所谓“对抗性蒸馏”密集发声,指责中国使用“蒸馏”这一广为业界使用的技术进行“知识产权窃取”,乃至造成“国家安全威胁”。4月以来,美国政企两端针对所谓“蒸馏”问题的动作不断升级:白宫科技政策办公室发布政策备忘录意在打击“蒸馏”,参众两院同步推进立法工作,再到OpenAI、Anthropic、谷歌借助“前沿模型论坛”建立企业间反蒸馏协同机制。“蒸馏”问题已经突破技术边界,成为美国多线协同的政策焦点,折射出美国对中国以开源模型为代表的人工智能创新成果的深层焦虑,将对全球人工智能创新与竞争态势产生进一步影响。
01
2026年4月23日,美国白宫科技政策办公室主任迈克尔·克拉西奥斯(Michael Kratsios)发布编号为NSTM-4的备忘录,题为《对抗性蒸馏美国人工智能模型》(Adversarial Distillation of American AI Models,下文简称备忘录)。备忘录宣称外国实体,尤其是位于中国的实体,正在以“蓄意、工业规模”的方式蒸馏美国前沿人工智能系统,并通过代理账户、规避检测手段,进行所谓“系统性抽取美国人工智能模型能力”的行为。对此,备忘录要求私营部门与政府强化信息共享机制,合作总结应对经验和处置方案,同时帮助企业间协同防御“蒸馏”、避免各自为战。在此基础上,探索溯源追责手段,考虑用各种手段去追责相关的外国行为者。
此外,备忘录虽承认“合法”蒸馏是人工智能生态的重要组成部分,并柔化姿态表示将继续支持开源生态和前沿人工智能的全球普及。但克拉西奥斯在备忘中强调,相关举措旨在“让美国人工智能能力可以更广泛地被使用……也要确保这种扩散是在‘可控’和‘公平竞争’的前提下进行。”换言之,要使全球人工智能竞争业态更符合美国自身利益。

迈克尔·克拉西奥斯(Michael Kratsios)出席听证会画面。来源:美联社
该备忘录回应了自今年年初以来,美国人工智能产业界内部愈演愈烈的“蒸馏”争议。今年2月23日,Anthropic发布官方通告指责三家中国人工智能实验室,使用海量虚假账户与其Claude模型进行了总计逾1600万次交互,截取Claude的技术能力、迭代优化自身模型。Anthropic声称这是“蒸馏”攻击,并将事情定性上升至国家安全层面,声称此举会对美国造成“重大国家安全风险”,同时在通告中借此强调美国对华人工智能芯片出口管制政策的战略必要性与合理性。OpenAI也附和类似论调,指责美国创新成果有被所谓“盗用和包装”的风险。
虽然两家公司CEO的紧张关系广为人知,但面对所谓的“对抗性蒸馏风险”积极寻求合作。4月初,彭博社援引知情人士的话报道称,OpenAI、Anthropic与谷歌三巨头试图通过“前沿模型论坛”这一平台共享信息,联手遏制中国竞争对手。而所谓“前沿模型论坛”,是这三家公司与微软在2023年共同创立的非营利性行业组织,原本以推进前沿模型安全研究和最佳实践为宗旨,至此被转作“反蒸馏”协同行动的运营平台——这一功能在论坛创立之初并未公开列入议程。彭博社报道称三家头部人工智能公司的合作实属“罕见”,凸显了其对相关问题的紧绷神经。

2月23日,Anthropic在官网发布公告指责包括Deepseek在内的三家中国人工智能实验室“恶意蒸馏”。来源:Anthropic官网
从当前政策布局看,美国以“蒸馏”为重点议题推动了内部整合和议程对齐,立法行政各条线得以多轨协同、统一步调。在备忘录中,克拉西奥斯还特别提到,相关举措是统一在特朗普政府2025年7月发布的《人工智能行动计划》框架里的,其中呼吁建立一个信息共享和分析中心,部分原因是为了遏制“对抗性数据蒸馏”。此外,备忘录的发布时机,也正值美国参众两院各自开展系列人工智能技术管制动作前后。4月22日,即备忘录发布前一日,美国众议院外交事务委员会推进一揽子出口管制法案,包括《硬件控制多边对齐法案》(MATCH Act, H.R. 8170)、《遏制芯片走私法案》(Stop Stealing Our Chips Act, H.R. 6322)、《威慑美国AI模型窃取法案》(Deterring American AI Model Theft Act, H.R. 8283)等,虽各有侧重,但共同加码在严控模型和算法能力扩散上,且均在委员会内部获得高票通过。所谓“限制中国获取先进芯片制造能力与美国闭源模型能力”的议题,已凝聚跨党派的高度共识和合作基础。同日,美国参议院司法委员会也召开听证会,围绕所谓“窃取美国创新”举行听证,本场听证会也将此前“窃取美国知识产权”的叙事延伸至“蒸馏”议题,也预示后续的出口管制与制裁工具将更精准地指向模型和算法层面。
此外,“蒸馏”话题促使美国“内外联动”,从技术话题拓展至外交领域。路透社独家报道称,据其看到的一份外交电报,美国国务院已下令在全球范围内采取行动,驻全球各地的使领馆与驻在地政府进行沟通,重点关注DeepSeek、月之暗面、MiniMax等中国主要人工智能企业,讨论所谓“广泛窃取美国人工智能实验室知识产权”的行为。至此,“蒸馏”话题已然“沸腾”,成为美国政界多轨协同下的话语焦点。其已经脱离了中性的技术范畴,而愈发在政策语境中与“知识产权窃取”“安全风险”等讨论框架捆绑,被打上了政治化、泛安全化的醒目标签。
02
“蒸馏”(Distillation)本是人工智能模型优化领域的一项基础技术。“蒸馏”最初被定义为一种“以强带弱”的教学机制,旨在通过大型模型的引导,培育出体积更小、更经济且运行高效的精简模型,使后者在大幅降低算力需求的同时,获得接近前者的性能表现。该技术由杰弗里·辛顿(Geoffrey Hinton)等人于2015年正式提出,迄今已是国际学术界与产业界人工智能研发的公认路径之一。学者纳森·兰伯特(Nathan Lambert)认为,当前大模型叙事下的“蒸馏”实质上更应被视为“合成数据生成”。业界在谈论“蒸馏”时,更多是指利用头部模型产出的合成数据作为原料,来优化或迭代其他模型的行为。
在Anthropic那篇指责“蒸馏”的公告中,也承认蒸馏是一种“行业普遍存在的迭代方法”。事实上在如今的人工智能行业,借助性能更优的模型输出来作为对齐数据训练自研模型,实现技术迭代,是行业默而识之的经验,不唯中国企业所独创。这在西方人工智能企业中也不乏先例,如斯坦福的Alpaca、加州大学伯克利分校的Vicuna这些代表性开源模型起初也是基于对GPT的输出数据进行蒸馏或者微调的。但当中国的人工智能企业循此路线时,却被扣上窃取的帽子,不免有“双标”之嫌,何况中国模型也会被美国企业“蒸馏”:今年3月,美国人工智能公司Anysphere旗下编程工具Cursor推出新模型Composer 2,最初宣传称其为“前沿水平”的“自研”成果——直至开发者在API响应中发现其内部模型ID为“kimi-k2p5-rl”,该公司联合创始人才承认Composer 2是基于月之暗面(Moonshot AI)开源模型Kimi K2.5的微调版本,仅约四分之一的算力来自其自身训练。相关事实爆料后,马斯克也在社交平台上跟帖“是的,那就是Kimi 2.5”。
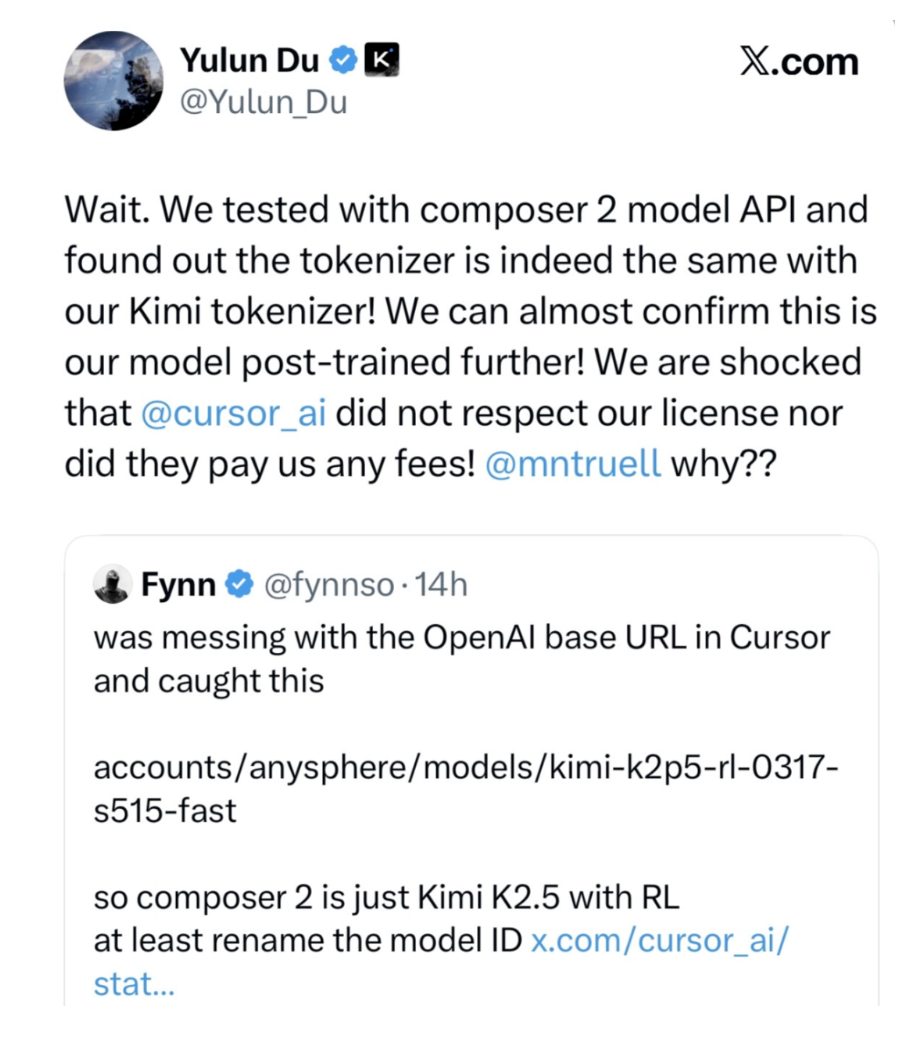
Composer 2是基于Kimi K2.5微调的事实在社交媒体上广泛传播
此前“蒸馏”争议主体尚处于模型厂商之间,“蒸馏”友商数据是否构成侵犯知识产权尚无判例可循,但是未经人类创作者授权的“蒸馏”训练已有判罚记录。以Anthropic自身为例,在2024至2025年间,其因涉嫌从“影子图书馆”下载约700万本盗版书籍训练模型,遭到多位作家的集体诉讼。2025年6月,加州法院作出裁定:虽然使用合法书籍训练可能属于“合理使用”,但从盗版库获取资源则构成了不可挽回的侵权。同年9月,Anthropic被判需支付至少15亿美元赔偿,创下美国版权赔偿纪录。因此,在今年2月Anthropic发布通告后,就遭到马斯克的揶揄:“怎么有人敢偷Anthropic从人类程序员那里偷来的东西?”
而如今,美国内部的产业和政府层面达成共识,明确将“蒸馏”定性为“窃取”。这一方面出于美国头部人工智能厂商存在护城河焦虑。目前,美国人工智能行业单次前沿大模型训练的投入已达数十亿乃至数百亿美元量级。在研发投入巨大的成本压力下,一旦竞争对手能够以极低成本通过蒸馏获取近似能力,前期的巨额投入就从集聚资本的优势变成了拉低收益率的劣势,因此争取政府力量介入以维护利益格局。另一方面,也反映了美国政府采取模糊化的策略推进技术问题政治化。备忘录对“蒸馏”的判断口径较宽,将调用美国模型的输出数据来训练自研模型,视为复制美国模型进而“偷窃”了其内部机制、训练数据和完整能力。由此有专家指出,备忘录把“从输出中学习”描述成“抽取美国创新”,在技术上过度简化,在政策上刻意放大。
03
跳出争议的表层水面,无论是美国人工智能产业界还是政界,都抱住“蒸馏”话题不放,意在坚持并宣传一个叙事:中国人工智能模型的飞速发展是基于美国的成果而非自主创新,在全球人工智能竞争中,美国依旧拥有不可替代的领先优势。但这些在技术原理和事实层面都经不起推敲——
其一,“蒸馏”固然是模型训练的捷径,但是无法替代模型的深层能力自主迭代创新。当前,前沿模型训练愈发依赖强化学习(Reinforcement Learning)、环境实时反馈(Real-time Environmental Feedback)和策略优化,“蒸馏”或许能让模型在部分任务中的表现贴近被“蒸馏”模型,但是深层的网络架构、推理效率优化等更核心的能力是无法通过“蒸馏”打包带走的。而这些领域恰恰涌现了大批中国开源模型的创新成果:DeepSeek的多头潜在注意力(Multi-head Latent Attention, MLA)、稀疏注意力机制(DeepSeek Sparse Attention,DSA)和混合专家架构(Mixture of Experts, MoE),以及Qwen的底座结构,在长文本处理、降低推理成本、世界知识等领域的表现都取得亮眼表现,与硅谷的顶级闭源模型并驾齐驱,其能力突破恰恰源于本土的高质量训练数据和算法迭代。因此,“蒸馏”叙事把中国大模型的整体进步简化为“蒸馏”甚至“复制”所得,严重低估了中国人工智能产业在开源协作、工程创新、数据治理等方面所取得创新实力,更高估了“蒸馏”所谓美国前沿模型在人工智能技术扩散起到的真实作用。
其二,中国大模型的自主开源成果正取得亮眼的市场反响。4月初,全球最大的人工智能大模型API聚合平台OpenRouter官方数据显示,DeepSeek-R1位列“全球最受欢迎模型”榜首,Qwen3.6-Plus和DeepSeek分别成为关注度最高和第四高的开源模型;其中Qwen衍生模型数量已超过11.3万个,远超Meta旗下Llama系列的2.7万个,开源贡献度居全球之首。这一格局在2026年4月24日DeepSeek V4预览版发布后更趋鲜明,V4-Pro以1.6万亿参数量成为目前全球规模最大的开源权重模型,其API输出定价仅为3.48美元/百万tokens,显著低于OpenAI、Anthropic、谷歌等同类前沿产品。值得注意的是,V4预览版恰与OpenAI的GPT-5.5模型同日发出,在白宫备忘录签发的次日推出,巧妙的时机也为当前全球人工智能创新与竞争形势写下生动注脚:一个由全球开发者“用脚投票”形成的真实生态,对于所谓“蒸馏”的污名化、政治化叙事是一种有力的消解。
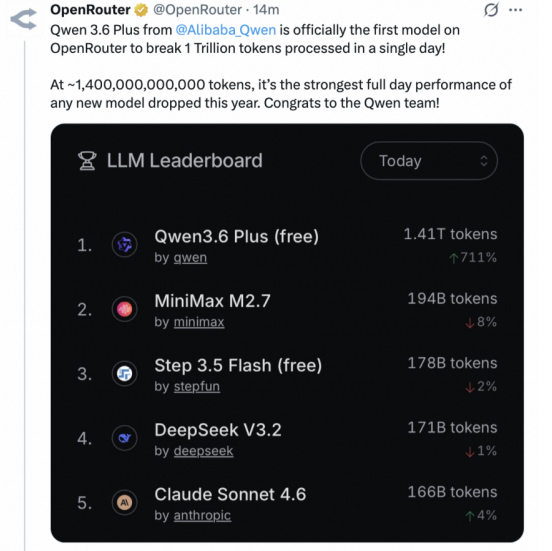
OpenRouter在社交媒体上称Qwen3.6-Plus破纪录,是“最强劲的新模型表现”。来源:X
“蒸馏争议”的迅速升温,折射出当前全球人工智能竞争已进入安全逻辑工具化与规则围剿的深水区。这起争议引人深思的不仅在于技术风险本身,更在于如何防止安全议题被滥用为排斥竞争的筹码。美国针对“蒸馏”的系列管制措施对于行业的短期冲击,或在于训练后期的对齐成本可能突然抬升、优质合成数据出现断档;而放眼长期,或将加速推动行业洗牌,倒逼各大模型企业加速底层创新,推动全球人工智能产业格局朝着多极化方向迈进。与此同时,包括我国在内的全球南方国家,正努力构建覆盖算力、数据与模型的人工智能自主生态,以技术自主的确定性应对外部环境的不确定性。全球人工智能的健康发展不应为单边定义的“安全禁区”所限,更不应沦为少数技术先发国维持领先地位的私产。倡导并构建一个超越地缘偏见、回归技术普惠的人工智能创新与治理的新秩序,需要国际社会共同参与,以更具体的技术贡献、更稳健的制度设计、更可信的多边参与,真正弥合智能鸿沟,在开放与共享中实现人工智能普惠发展。

CopyRight©2007 复旦发展研究院版权所有 备案号/经营许可号:沪ICP备05006147号
地址:上海市邯郸路220号智库楼 邮编:200433 电话:86-21-55670203 传真:86-21-55670203
电子邮箱:fdifudan@fudan.edu.cn
