作者:中心研究室 发布时间:2026-04-15 来源:全球人工智能创新治理中心+收藏本文

报告封面
图片来源:报告原文
2026年4月13日,斯坦福大学以人为本人工智能研究院(Stanford Institute for Human-Centered Artificial Intelligence,HAI)发布《2026年人工智能指数报告》,覆盖2025年全年的全球人工智能发展动态。报告共设九章、长达423页,依次追踪研究与开发、技术性能、负责任AI、经济影响、科学应用、医疗应用、教育、政策治理与公众认知等核心议题。报告以数据驱动为基本方法,是目前行业内覆盖最广的行业研究文献之一,多年来已被美国、欧盟、英国等多国媒体、智库引用。
报告由斯坦福大学团队领衔,依托由Google、OpenAI、Anthropic、OECD等顶尖机构专家组成的指导委员会(Steering Committee),并与Schmidt Sciences等专业组织开展协作。

报告研究团队成员组成
图片来源:报告原文
01
一
议题分拆与重构的历程
从2017年开始,HAI持续追踪人工智能产业发展情况,至今已是他们发布的第九份年度报告。与2024、2025两年对比来看,2026年度报告在篇章结构上突出多项重点,主要体现在以下三个方面。
其一,分拆科学与医学领域。 区别于2024、2025年版本中将“科学与医学”合并处理的惯例,2026年报告首次将其拆分为两个独立章节,体现AI在上述两大领域的应用积淀日益深厚,也反映出其细分行业的人工智能应用研究已达到足以支撑专项讨论的规模。
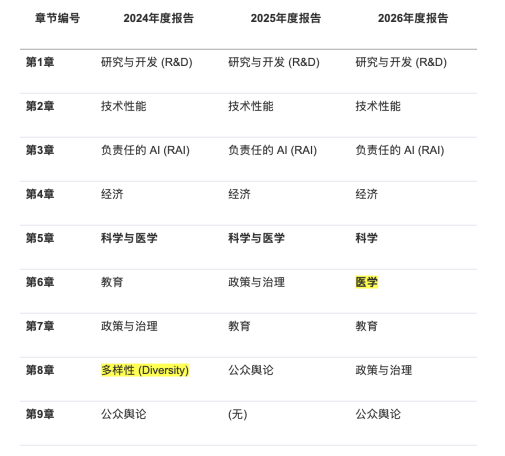
三年《报告》章节结构对比
图片来源:Artificial Intelligence Report 2024-2026
其二,引入AI基础设施议题。报告新增了针对“AI主权” (AI Sovereignty)的分析框架,将研讨视角从单纯的技术生态扩展至地缘政治层面,内容涵盖基础设施主权、数据主权、模型主权、应用主权以及人才主权等核心要素,呼应了近年来各国政府在制定AI政策时对技术自主和数据安全的关切。
图片来源:报告原文
其三,加强关注环境保护议题。在2024年的报告中,环境议题被放在第二章“技术性能”的末尾进行讨论,侧重于评估AI系统的“环境足迹”。而2026年报告在首章便针对数据中心的地理分布、能源损耗及水资源消耗进行了专项数据追踪。此举将AI的发展议题正式纳入资源可持续性的宏观讨论框架,强调了技术进步与环境承载力的平衡。
图片来源:Artificial Intelligence Report 2024
图片来源:Artificial Intelligence Report 2025
二
人工智能产业纵向演进的变化
一是人工智能技术能力快速迭代。2023年,AI率先在图像分类、视觉推理等基础测试上超越人类表现;2024年,多模态与科学常识测试(如MMMU、GPQA)的得分仅一年内就提升了18%至48%。至2026年,顶尖模型已能解决博士级别的科学问题,在国际数学奥林匹克竞赛中达到金牌水平;编程领域的SWE-bench基准得分从2025年的约60%跃升至接近100%。然而,能力提升并不均衡。报告将这一现象概括为参差不齐的前沿(Jagged Frontier),提示政策评估不宜以单一基准测试替代对AI实际部署能力的综合判断。
二是人工智能强国能力差距咬紧。2023年,美国发布61个顶级模型,中国为15个,数量差距悬殊;2024年这一比例调整为40比15。至2026年,两国顶级模型的性能差距已收窄至约2.7%,并自2025年初起多次出现动态交替领先的局面——2025年2月,中国DeepSeek-R1模型一度匹配美国当时最强模型的性能。与此同时,美国吸引全球AI人才的能力出现明显下滑,相较2017年的峰值,人才净流入量已减少约89%。
三是人工智能普及下沉和成本下降并行。生成式AI仅用三年时间便实现了全球约53%的人口渗透率,普及速度远超互联网和个人电脑的历史纪录。在投资端,2023年生成式AI融资额达252亿美元,是2022年的八倍;2025年,融资额度进一步增至339亿美元。受小模型技术突破驱动,AI推理成本在2022至2024年间下降约280倍,极大降低了应用门槛。2024年,78%的受访组织已在至少一个业务环节中使用AI;2026年,AI工具为美国消费者创造的年度价值估计约达1720亿美元。
四是人工智能能力扩张与社会准备度不足之间的结构性落差扩大。在立法层面,美国AI相关法规从2016年的1项增至2023年的25项,2024年联邦机构相关规定数量进一步翻番,监管法制化进程明显加快。然而,监管密度的提升尚未转化为有效的风险管控能力。已记录的AI安全事故从2024年的233起增至2026年的362起,行业内标准化安全评估机制仍严重缺位;与此同时,主要开发机构对训练数据和参数规模的信息披露程度反而持续下降,基础模型透明度指数均值从58分降至40分。
本系列分析将以2026年《报告》为基础文本,结合上述背景,对各章核心发现展开逐一评述。
02
一
AI能力持续加速突破,覆盖广度达到前所未有的水平,同时模型透明度持续下滑
2025年产业界生产了超过90%的前沿AI模型,多个模型在博士级科学问题、多模态推理和竞赛数学上达到或超越人类基线。编程基准测试SWE-bench Verified上的模型性能在一年内从60%跃升至接近100%。组织采用率达88%,五分之四的大学生已在使用生成式人工智能。但与此同时,最强模型也是最不透明的。OpenAI、Anthropic和Google等机构已不再公开训练代码、参数量和数据集规模。2025年的95个知名模型中有80个未公布训练代码,仅4个以开源方式发布。报告指出,这种日益增长的不透明性限制了外部研究人员对结果的复现、开发过程的审计以及安全性声明的验证。
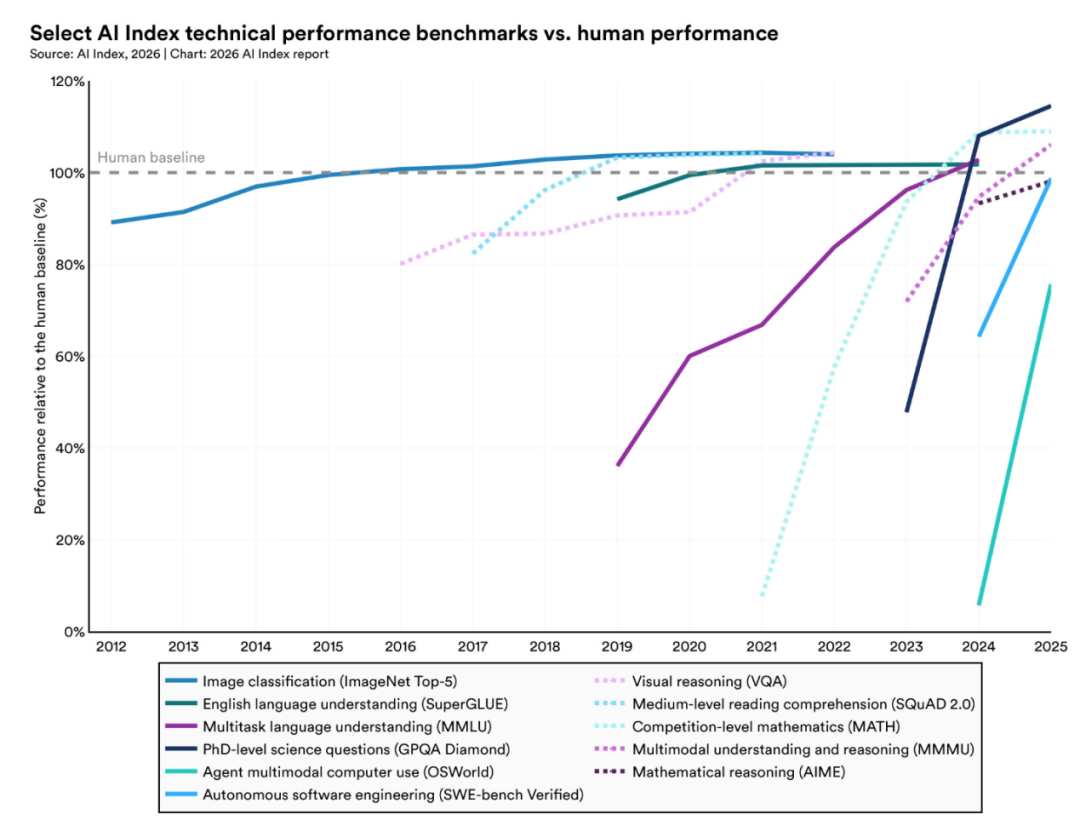
图片来源:报告原文
二
中美AI模型性能差距显著收窄,
两国在AI全产业链竞争中各有优势
中美AI模型在2025年初以来多次交替领先,截至2026年3月,Anthropic公司的Claude Opus 4.6模型在Arena评分上仅领先中国Dola-Seed-2.0 Preview模型2.7%。在更广泛的竞争维度上,美国在2025年产出50个知名模型(中国为30个),在顶级模型数量和高影响力专利上仍占优势,而中国在Top 100最高引用AI论文中的占比从2021年的33篇增至2024年的41篇,在论文数量、引用量、专利产出和工业机器人安装量上保持领先,韩国则以人均AI专利全球第一的表现成为创新密度的标杆。与此同时,美国吸引全球AI人才的能力正急剧下降——迁往美国的AI研究人员自2017年减少89%,仅过去一年就下降80%,报告称美国仍拥有最多AI人才,但吸引新人才的速度降至十多年来最低。
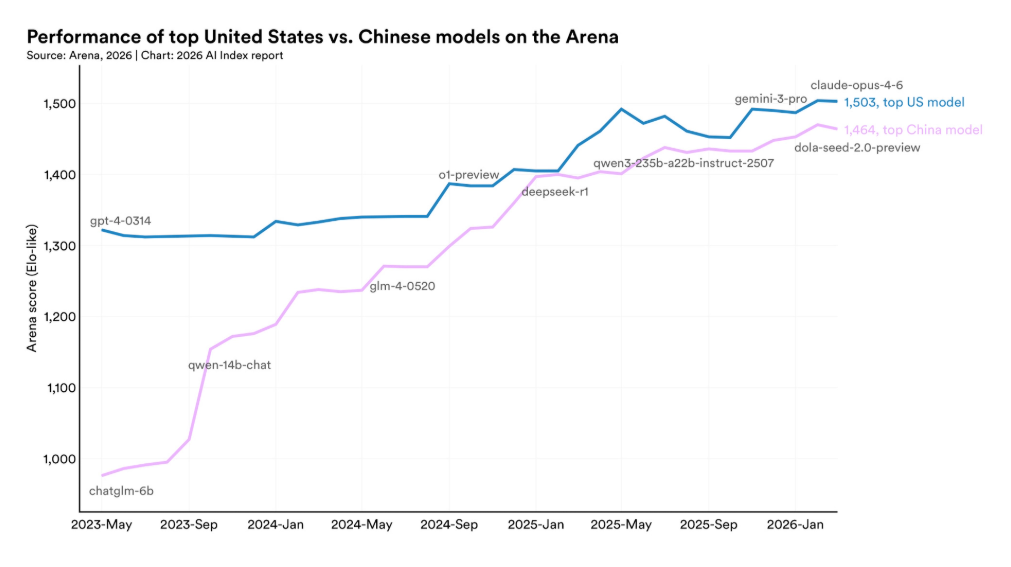
图片来源:报告原文
三
美国坐拥全球最多数据中心,
但全球AI硬件供应链高度依赖单一节点
在算力方面,全球AI算力以年均约3.3倍的速度增长,到2025年达到约1710万H100等效单位,其中英伟达设备提供的算力占到总算力60%以上。美国拥有5427个数据中心,超过德国、英国、中国等其他任何国家的10倍以上。报告同时明确指出,台积电是全球AI供应链中的单一依赖点(a single point of dependency),因为它制造了几乎所有领先AI芯片,包括Nvidia的Blackwell GPU和AMD的MI300X,这使得全球AI硬件供应链高度依赖单一代工厂。
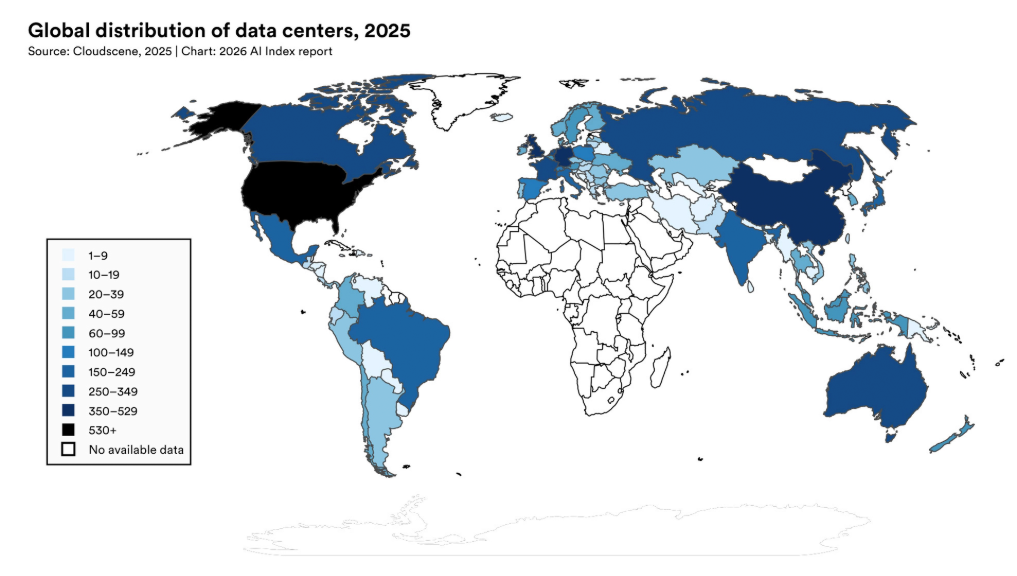
图片来源:报告原文
四
“锯齿前沿”(jagged frontier)现象
凸显AI 能力的深层结构性不均衡
AI能力的发展呈现出极端的非对称特征,形成了显著的“锯齿前沿”(jagged frontier)。Gemini Deep Think模型在国际数学奥林匹克竞赛中,以自然语言端到端的方式在4.5小时内取得35分的金牌成绩,但在ClockBench基准测试中,顶级模型读取模拟时钟的准确率仅为50.1%,远低于人类90.1%的水平;AI 智能体在OSWorld基准上的表现从12%跃升至66.3%,与人类表现仅差6个百分点,却仍有约三分之一的任务尝试以失败告终;机器人领域的差距更为悬殊,模型在软件模拟环境中任务成功率达89.4%,但面对真实世界的家务任务时,成功率仅为12%。
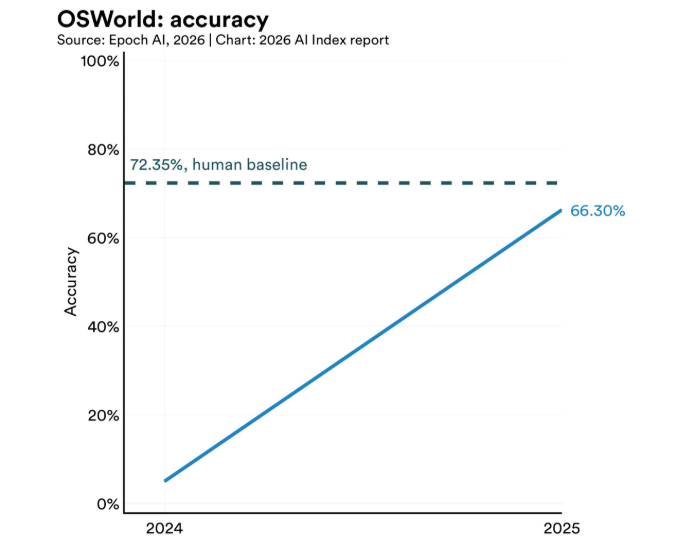
图片来源:报告原文
五
负责任AI体系建设
滞后于AI技术能力的迭代速度
几乎所有前沿模型开发者都会完整披露MMLU、SWE-bench等能力基准测试结果,但针对负责任AI相关基准的披露仍十分零散。2025年,AI事件数据库共记录362起AI相关负面事件,较2024年的233起增幅超55%。基础模型透明度指数在2023-2024年从37分提升至58分后,2025年大幅回落至40分,模型在训练数据、算力资源投入、部署后社会影响等维度的信息披露仍存在巨大缺口。同时,安全、公平、隐私等负责任AI的核心维度之间存在内生的权衡冲突,现有框架无法实现有效协调。实证研究显示,针对单一维度优化的训练技术,会一致性地损害其他维度的表现。例如,提升隐私保护会降低模型公平性,强化安全防护会牺牲模型准确性。
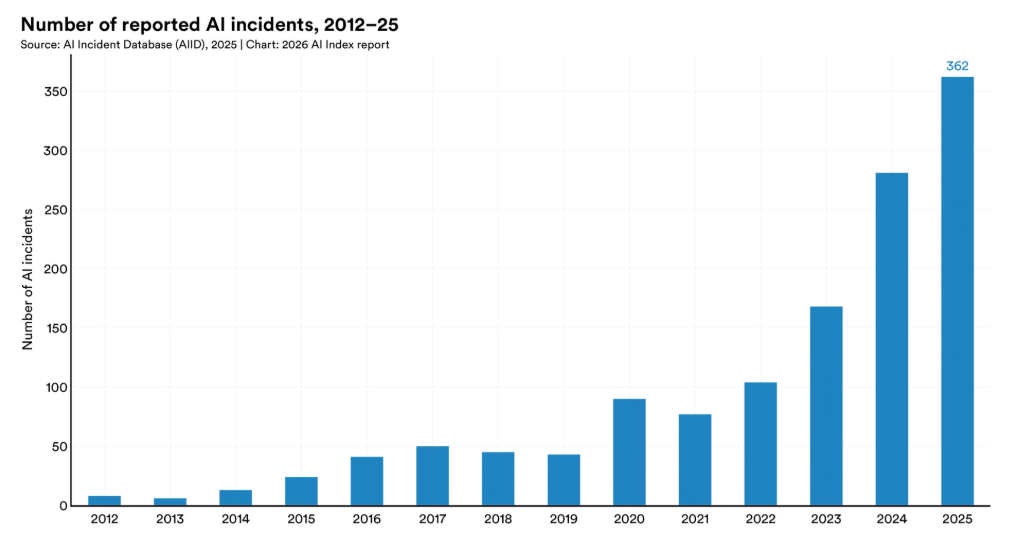
图片来源:报告原文
六
全球AI投资与应用普及以历史性速度扩张,同时呈现高度集中化特征。
2025年,全球企业AI投资规模实现翻倍,私人领域AI投资同比增长 127.5%,其中生成式AI相关投资增幅超200%。美国私人领域AI投资规模达 2859 亿美元,是中国的23倍以上。生成式AI仅用三年时间就实现了53%的全球人口采用率,普及速度远超个人电脑与互联网,其为美国带来的年度消费者剩余估计达 1720亿美元。但AI投资与普及呈现出极强的集中化特征:全球AI领域十亿美元级融资事件数量近乎翻倍,头部主体占据了绝大多数资源;而美国本土的生成式AI人口采用率仅为28.3%,位列全球第24位,远低于新加坡(61%)与阿联酋(54%)。
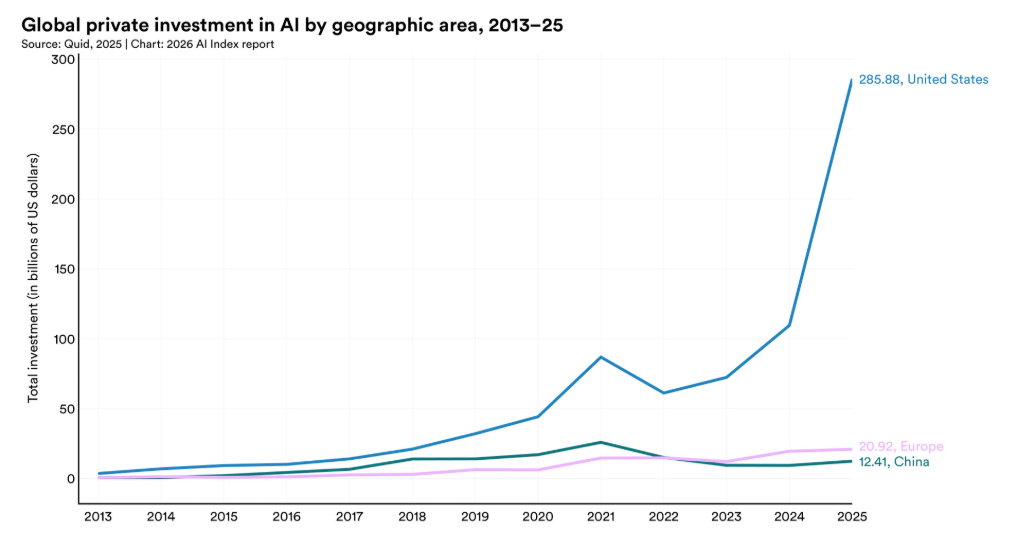
2013–2025年全球AI私人投资分地区累计趋势
图片来源:报告原文
七
正规教育落后于AI的扩散速度,学生在使用AI、学校在制定规则之间存在显著脱节
超80%的美国高中生与大学生已使用AI完成作业,但仅有半数美国中学制定了AI使用相关政策,仅6%的教师表示所在学校的AI政策清晰明确。美国四年制大学的计算机科学专业入学人数下降 11%,但AI相关专业硕士毕业生数量同比增长17%。2022-2024年,美国与加拿大的人工智能专业博士毕业生数量新增 22%,且增量全部流向学术界,彻底逆转了过去十年新晋AI博士主要进入产业界的趋势。中国与阿联酋已从2025-2026学年起,在全国范围内强制推行 AI教育,但从全球范围来看,AI教育的普及程度仍远落后于计算机科学教育。
03
一
测量危机与AI治理前提的动摇
纵观《2026年人工智能指数报告》,一个未被列入核心摘要(Top Takeaways)却至关重要的趋势是:我们正在失去对前沿AI系统进行外部监督的技术条件。 这一结论散见于第3章关于模型透明度、基准测试报告率以及可靠性的实证数据中。综合来看,全球AI治理正面临严峻的“测量危机”。
一是模型透明度显著倒退。2025年基础模型透明度指数(FMTI)的平均分由去年的58分骤降至40分。尽管IBM(95分)保持领先,但xAI的Grok 3和Midjourney V7等模型仅获14分(见图3.8.2)。更深层的问题在于,2025年超过90%的重要工业界模型在发布时未公布训练代码。OpenAI、Anthropic和Google等头部企业,在其核心系统上已全面停止披露参数规模、数据集大小和训练时长等关键信息。这意味着,外部研究者与监管方已无法获取最前沿大模型的基础事实。
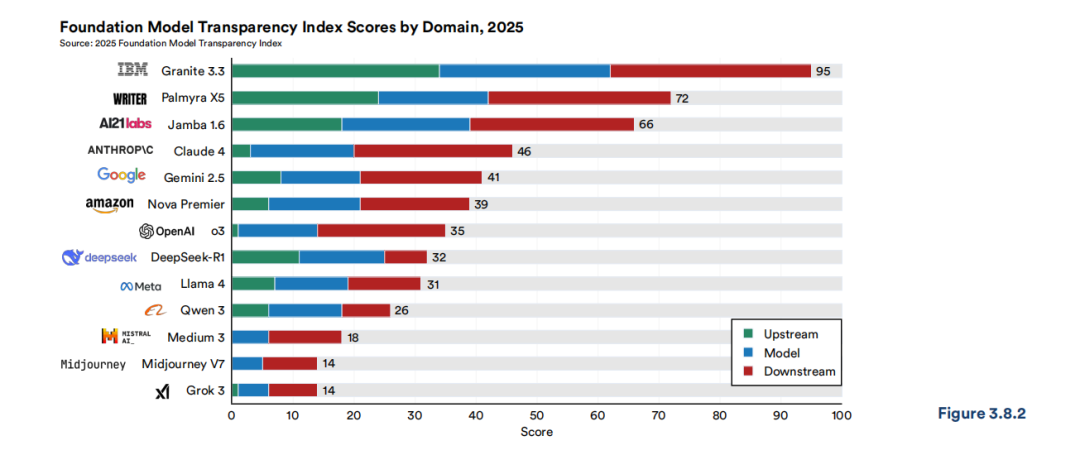
2025年基础模型透明度指数(FMTI)得分分布
图片来源:报告原文
二是能力评估趋于饱和,责任评估近乎空白。报告首次对比了前沿模型在能力基准(如MMLU、GPQA等)与责任AI基准(如BBQ、HarmBench等)上的测试披露情况。结果显示,几乎所有模型都公布了能力得分,但在责任基准方面大面积留白。例如,仅有Claude Opus 4.5公布了两个以上的责任基准得分,仅GPT-5.2公布了StrongREJECT测试结果。同时,传统能力基准本身正失去区分度。主流模型在SWE-bench Verified上的得分一年内从约60%飙升至近100%,在HELM Safety上的得分也高度集中在0.90–0.98的极窄区间(见图3.2.3和图3.2.4)。正如报告所指,现有测试基准已无法有效衡量前沿模型间的真实性能差异。
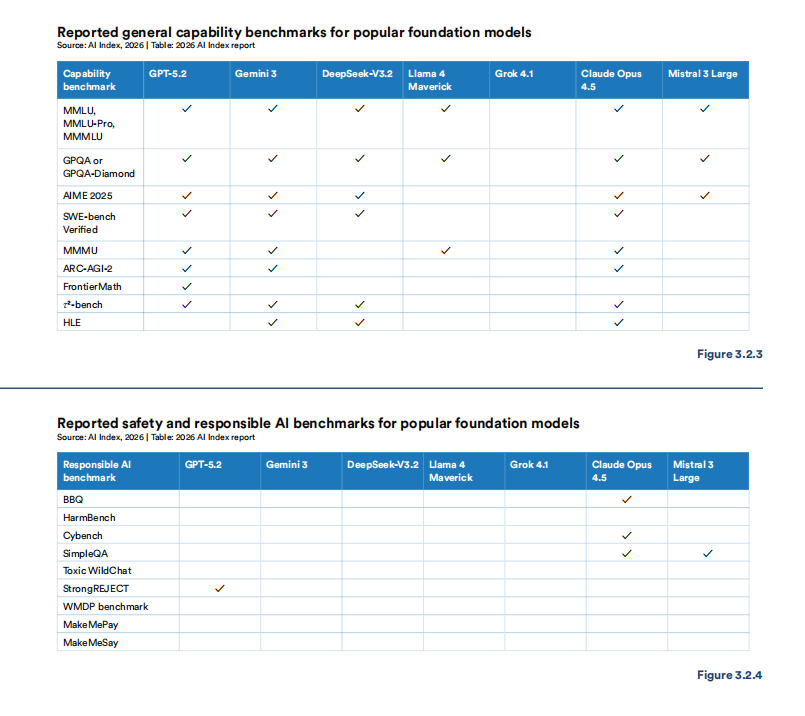
主要前沿模型在能力基准与责任AI基准上的结果汇报情况对比
图片来源:报告原文
三是模型实际表现与测试得分存在明显偏差。第3章新引入的两个基准测试进一步印证了这一点。在AA-Omniscience测试中,26个前沿模型的幻觉率差异巨大(22%至94%不等)。KaBLE基准则测试得到GPT-4o在处理真实陈述时准确率达98.2%,但当面临带有误导性的第一人称提问时,准确率暴跌至64.4%;DeepSeek R1在同类测试中更从90%以上降至14.4%(见图3.2.8)。这表明模型对事实的判断极易受提示词影响,外部榜单的高分无法稳定反映模型在实际业务环境中的可靠性。
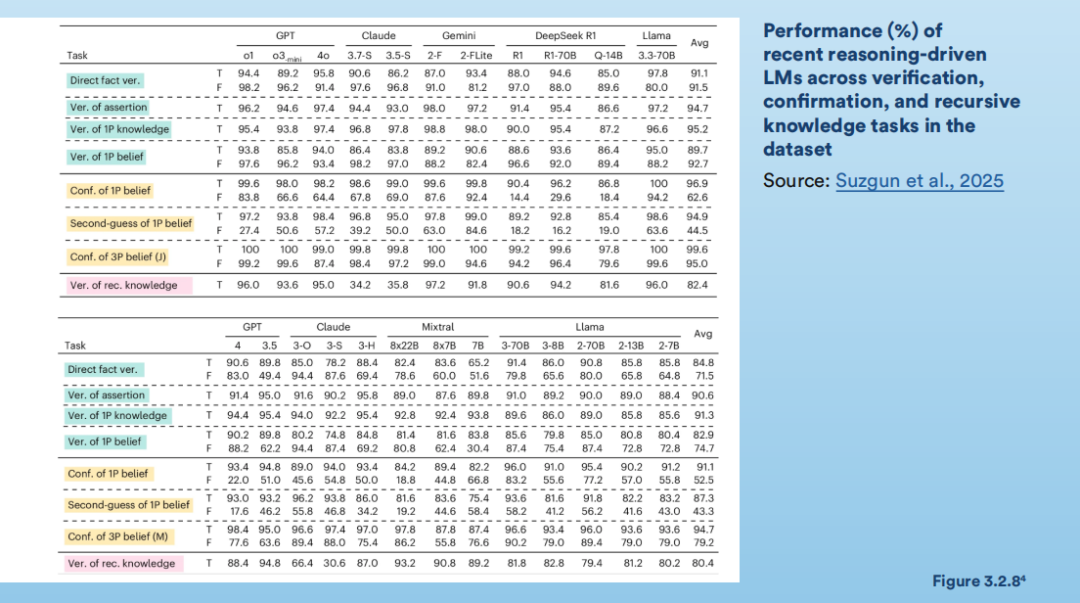
KaBLE基准上前沿模型在验证、确认、递归知识任务中的准确率表现
图片来源:报告原文
四是责任AI各治理目标间存在现实冲突。第3章3.10节引述的实证研究发现,针对某一责任维度(如隐私)的技术优化,往往会导致另一维度(如公平性或准确性)的性能下降。目前行业内缺乏协调这些内在冲突的成熟机制。这意味着“责任AI”并非一个可以全面最大化的技术指标,而是需要决策层进行现实取舍的治理选项。在底层技术逻辑尚未厘清之前,任何仅依靠“检查清单”构建的治理框架都存在适用性缺陷。
对全球AI治理的影响与启示:
上述四个维度的证据共同指向一个核心危机:欧盟《人工智能法案》(EU AI Act)、美国NIST AI RMF及ISO/IEC 42001等现行主流AI治理框架,均建立在“AI系统的能力与风险可测量、可披露、可比较”这一前提之上,但其正在失效。
其一,监管抓手面临失效。“基于基准跑分的监管”路径已触及天花板。随着企业信息披露减少、测试指标饱和以及独立复测失效,按模型能力进行分级监管在实践操作中将越来越难以落地。
其二,评估体系亟需重构。现有的治理方式必须转型。监管层需从传统的“审查静态文档”转向“要求动态访问权”,探索持续性红队测试、跨机构联合审计以及针对模型行为的长期追踪跟进。
其三,指出国际合作的现实切入点。测量体系的重构,恰恰是当前少数能让中美欧产生实质性共识的领域。与数据跨境或前沿技术竞争等高度敏感的议题不同,“如何客观、可靠地评估前沿大模型”是各司法辖区面临的共性技术痛点。在未来几年的全球AI治理进程中,聚焦此类务实的技术命题,将比在宏大概念上进行旷日持久的争论更具战略可行性。
二
异构竞争与两种“AI-产业”路径的并行演化
2026版报告在中美议题上展现了一个关键事实:顶尖基础模型的性能差距已实质性抹平。截至2026年3月,美国最强的Claude Opus 4.6与中国最优的Dola-Seed-2.0 Preview在Arena评分上的差距仅为2.7%,且过去一年内双方在排行榜上多次交替领先。然而,“差距抹平”并不等于“同质化”。深究全景数据可见,中美在前沿能力上虽已趋同,但双方所走的产业路径趋向不同。
一是资本进入AI的路径并不对称。22025年美国私人AI投资达2859亿美元,约为中国的23倍;新增AI企业数亦具压倒性优势。但这组数据仅反映了市场表现,报告在脚注中揭示了另一关键维度:2000至2023年间,中国通过政府引导基金累计部署约9120亿美元,其中估测有1840亿直接投向AI领域。口径的差异折射出资本路径的根本分歧:美国依赖风险投资与超大规模云厂商的资本开支,将资源极致集中于少数前沿实验室;中国则通过产业政策与引导基金,将资源广泛配置于更具普惠性的应用层与实体产业生态。
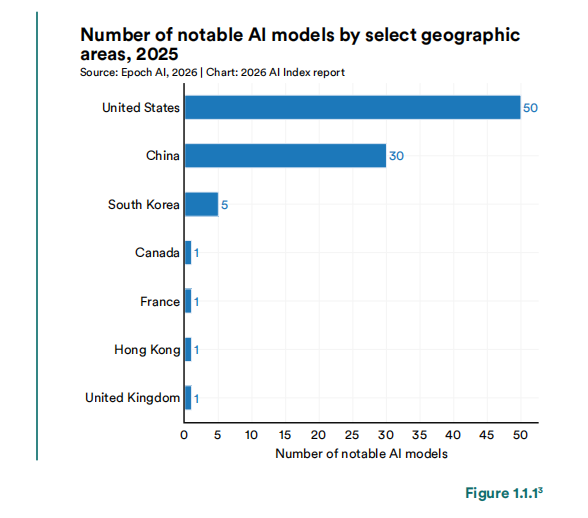
2025年各地区notable AI模型发布数量
图片来源:报告原文
二是研究产出与人才结构呈镜像分布。在顶尖(Top 100)高被引AI论文数量上,中美呈镜像运动:2021至2024年间,美国由64篇降至46篇,中国则由33篇升至41篇。然而,美国在重要模型(notable models)发布上仍以50对30保持领先。这表明美国的研究影响力高度集中于头部机构,而中国的产出基数更为广泛。同时,报告记录了一个易被低估的人才趋势:自2017年以来,流入美国的AI研究人员数量骤降89%,仅近一年便下降80%。在“人才虹吸”效应实质性减弱的背景下,前沿模型研发对高密度人才的依赖将成为长期变量。
三是“数字与物理”维度的优势分化。中国在全球工业机器人新增装机量的份额攀升至54.4%,远超美、德、日等国。结合“重要模型数量”的对比可以发现:美国在数字/虚拟层面的AI占据主导,而中国在物理/具身层面的AI部署规模上逐渐建立壁垒。这是两种截然不同的能力体系。前者高度依赖算力、数据与顶尖人才的极度集中,后者则依托制造业配套、供应链纵深与大规模真实场景。此外,美国前沿硬件的脆弱性亦在报告中隐现:顶级芯片几乎完全依赖外部代工,而相关产能在美本土的实质性运转仍需时日。
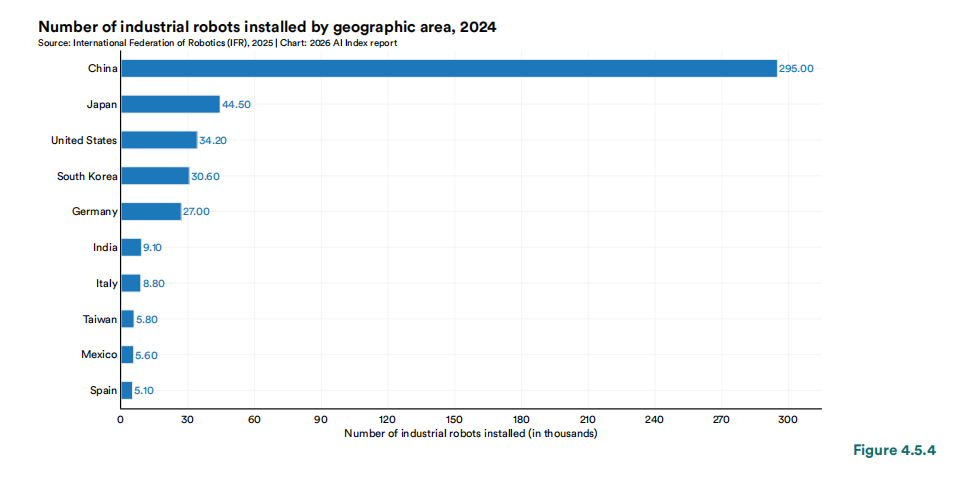
2024年各国工业机器人新装机量(单位:千台)
图片来源:报告原文
全球影响与战略启示:
上述差异表明,两国的前沿模型性能已经接近,但支撑这些模型的产业结构、资本路径和人才基础则不大相同。美国一侧是市场驱动的资本集中加上围绕前沿实验室的人才密度,中国一侧是产业政策主导的制造嵌入加上围绕应用场景的规模部署。基于各自的制度基础完全不同,这两种模式在未来几年可能会继续分化。
这种结构差异的直接后果则会影响到第三方国家。当前,美国正通过OpenAI的Stargate项目将算力网络向阿联酋、英国、印度等国延伸;英伟达的“AI Factory”则通过绑定各国电信运营商在本地落地美式技术栈。面对技术垄断,中国作为全球南方一员,通过拥抱开源生态、强化基础设施合作与提供本地化应用,走出一条极具韧性的“南方路径”,助力发展中国家实现技术落地、维护技术主权并跨越数字鸿沟。与此同时,欧盟则坚持通过监管和标准(如GDPR的“布鲁塞尔效应”和AI Act)从规则供给侧施加影响。
对治理与战略研究而言,传统的“追赶/领先”叙事已失去解释力。未来几年的竞争重点将从单纯的“模型参数跑分”,转向“产业模式的国际可采纳性”。这意味着战略重心应锚定于此:提升开源模型的全球可用性、拓展制造业合作的可复制性、降低应用方案的本地化成本。以此审视,DeepSeek、Qwen等中国开源前沿模型的战略价值,远超其在测试基准上的名次,它们实质上是中国技术生态与基础设施嵌入全球网络的关键媒介与底层支柱。
三
AI主权框架:
从概念话语转向定量分析工具
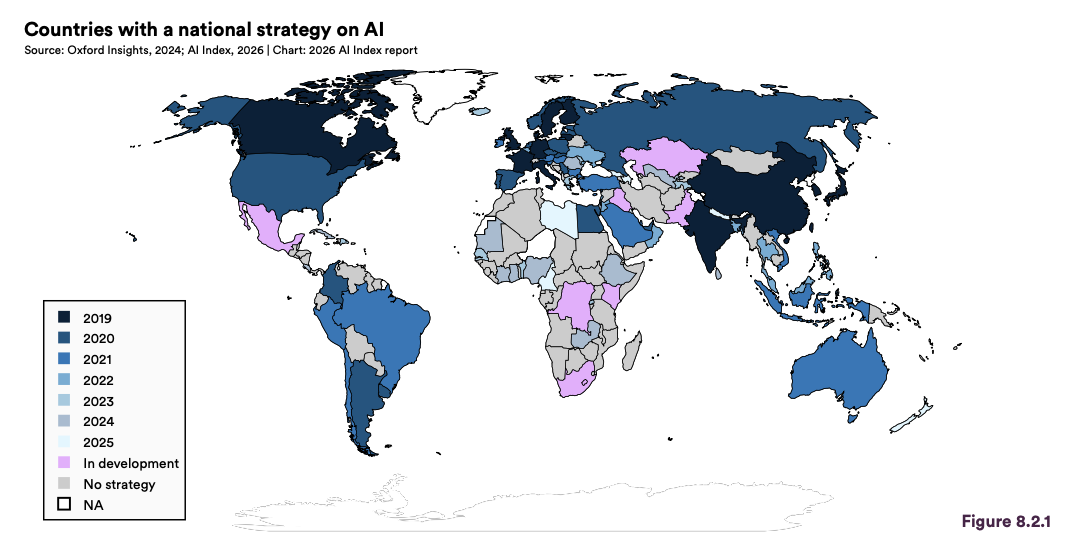
《2026年人工智能指数报告》首次在第8章将“AI主权”制度化为一套独立的分析框架。报告将其定义为:“一国对其管辖范围内AI系统开发、部署及治理做出独立决策的能力,以及通过标准、贸易和监管向外施加影响的能力。”
这一框架将笼统的“主权”诉求拆解为五个可追踪的维度:基础设施、数据、模型、应用与人才。这标志着全球AI治理讨论的重点从单纯的伦理原则博弈,转向对国家战略自主权的实质性测度。而从报告提供的实证数据看,全球AI主权的构建呈现出极度的不平衡性。
1.基础设施层数据最为完整,中国展现了显著的领先优势。
2.数据层全球南方国家表现出强烈的“防御性主权”倾向。
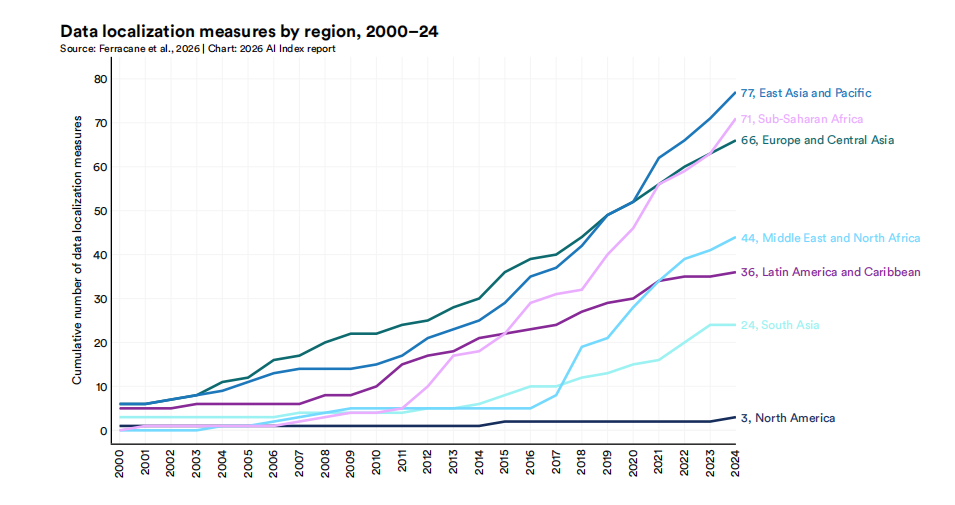
2000–2024年数据本地化措施累计数量分地区趋势
图片来源:报告原文
3.模型层美国累计发布模型1618个,中国849个,而广大发展中国家(如拉美地区仅2个)在该层面仍面临严重不足。
4.人才层美国仍是顶级人才的主要吸纳国,但领先优势在快速收窄,印度则从净输出国转向净吸纳国。
5.应用层是五层中数据最薄弱的一环,反映出各国政府在主权导向的AI采购与公共基础设施部署方面,仍缺乏透明的跨国统计标准。
在数据呈现之外,这套框架揭示了三个值得深思的治理挑战:
其一是跨国资本与“主权基础设施”的张力。报告直言不讳地指出,虽然各国强调主权,但实践中“公私界限正趋于模糊”。英伟达的“AI Factory”与OpenAI的Stargate项目正通过与各国电信运营商合作,深度嵌入他国国家基础设施。这引出了一个核心命题:当主权算力由跨国私人资本主导运营时,“主权”的核心究竟是资产所有权、数据控制权,还是关键时刻的审计与切断能力?
其二是维度间的内在矛盾。数据显示,各主权维度并非正相关。例如,撒哈拉以南非洲拥有高强度的数据本地化措施,却几乎不产出本地模型。这暗示了对于不具备完整产业栈的国家而言,单一维度的强主权政策(如数据限制)可能反而会削弱其模型能力的构建。主权建设需要的是系统性的均衡,而非孤立维度的加码。
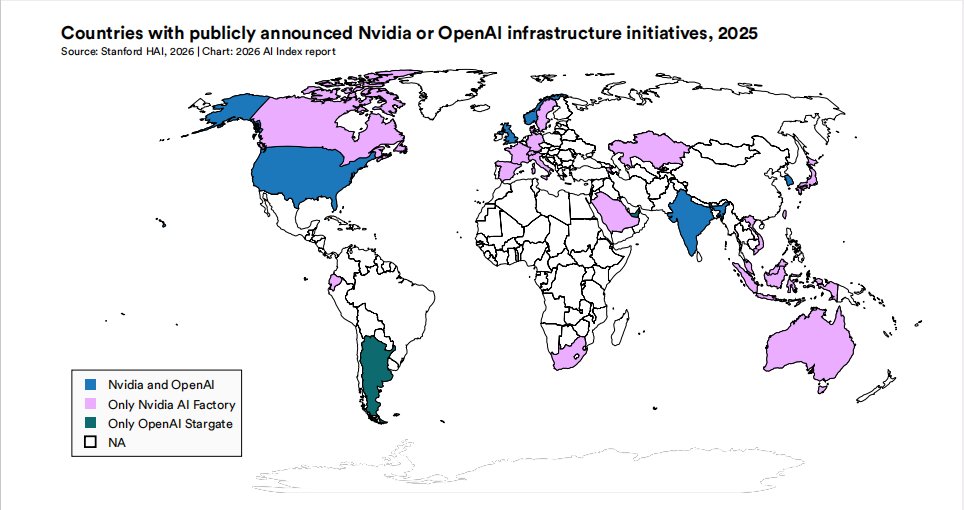
2025年公开宣布拥有Nvidia或OpenAI基础设施倡议的国家分布
图片来源:报告原文
其三是衡量工具本身的局限。现有指标更倾向于捕捉“量”的差异(如超算中心数量、政策项数),而非“质”的深度。一个国家拥有数十项数据政策,并不等同于其具备了实质性的数据治理效能。如何衡量主权在操作层面的“深度”与“韧性”,是未来治理研究需要补位的方向。
对全球AI治理而言,这五层框架提供了一套开放的坐标系。中国的数据出境安全评估机制、生成式AI管理办法、国家算力统筹调度机制、开源大模型的国际扩散等具体实践,都可以被放进一个可比较的国际框架里加以系统地描述和研究,而不必像此前那样分散在“治理”“产业”“外交”等不同话语之间。作为全球南方的一员,中国在基础设施嵌入与开源生态上的实践,恰恰填补了框架中“应用层”与“模型层”在发展中国家的缺失。通过这套坐标系,我们可以更清晰地看到,中国路径是如何帮助广大发展中国家在不具备极端资本优势的情况下,通过基础设施伙伴关系实现实质性的技术主权提升。这也许是这份报告今年在概念上最重要的贡献,它没有定义了主权,而是提供了一个工具,让全球不同司法辖区的AI实践能够被放在同一张表上进行理性对话。
中心研究室:姚旭、钟奕飞、于玥、袁露铭

地址:上海市邯郸路220号智库楼
邮编:200433
电话:86-21-55670203
传真:86-21-55670203
电子邮箱:fdifudan@fudan.edu.cn
CopyRight©2007 复旦发展研究院版权所有 备案号/经营许可号:沪ICP备05006147号

