作者:于玥 发布时间:2026-05-17 来源:全球人工智能创新治理中心+收藏本文
编者按
当前,全球前沿人工智能技术迭代持续加速,其在军事指挥、情报分析、网络作战等国家安全领域的应用不断深化。人工智能对齐(AI Alignment)是指确保人工智能系统始终按照人类真实意图与预设目标行动、避免偏离任务初衷的技术与治理过程,是保障AI安全、可靠、可控的核心环节。美国新安全中心(Center for a New American Security, CNAS)研究团队在《Off Target:A Working Paper on AI Alignment Challenges for National Security》报告中指出,国家安全领域AI应用的核心约束正从“能力不足”转向“信任缺失”,对齐风险(Alignment Risk)将成为决定AI军事价值的关键瓶颈,报告也为美国政府构建专业化、体系化的人工智能对齐治理能力提供了系统性政策建议。
作者介绍
Caleb Withers,美国新安全中心(CNAS)技术与国家安全项目研究员;Jay Kim,进步研究所(Institute for Progress)实习生;Ethan Chiu,耶鲁大学历史系本科生。
01
一
前沿AI发展与国家安全应用态势
前沿人工智能技术的能力迭代速度不断加快,在情报数据分析、网络作战支持、军事行动规划等国家安全场景中,展现出变革性的应用潜力。美国及其战略竞争对手均将AI视为重塑军事优势的核心技术,美国国防部于2026年1月发布的AI加速战略,明确提出要打造全域“AI优先”作战部队,并认为技术部署滞后的风险高于对齐不完善的风险。但随着技术落地进程加快,人工智能对齐(即确保AI系统始终执行预设目标的能力)的重要性日益凸显。2026年初,美国国防部与人工智能企业Anthropic产生的分歧,也反映出各方在军事领域模型可靠性与对齐问题上的认知差异。
过去,AI应用的核心限制在于系统能力不足,难以处理复杂非结构化情报、统筹作战规划或自主执行网络行动。而随着前沿模型能力实现突破,信任问题已取代能力不足,成为AI应用于国家安全领域的核心约束。AI系统被对手攻击与对齐失效是两类独立风险,二者虽可共用部分检测与缓解工具,但对齐失效具有独特属性:它可在无外部干预的情况下,由训练过程自然产生,且会随系统能力提升而不断恶化。报告系统梳理了前沿模型对齐研究的现状,分析了对齐失效的表现形式与实证依据,明确了高风险应用场景,最终提出了面向国家安全领域的治理与应对建议。
二
报告研究框架与核心价值
报告聚焦人工智能对齐在国家安全领域的独特挑战。首先,报告界定了对齐失效的定义、类型与内在机理,对比了其与常规系统故障的本质差异;其次,梳理了2025年以来前沿大模型对齐研究的关键发现,揭示了训练范式转变带来的结构性风险;随后,评估了对齐失效在军事指挥、情报分析、网络作战等场景中的具体危害,明确了风险最高的应用方向;最后,结合美国2026财年国防授权法案的要求,提出了联邦政府可落地的能力建设与政策工具。
该报告的核心价值在于打破了“能力优先于安全”的技术部署惯性,首次系统论证了国家安全场景下人工智能对齐失效的不可预测性、能力放大性与长期危害性,为政府从AI技术消费者转变为治理主导者,提供了理论支撑与实践路径,填补了前沿AI技术与国家安全治理交叉领域的研究空白。

图片来源:IEEE Spectrum
02
一
传统可靠性体系的失效
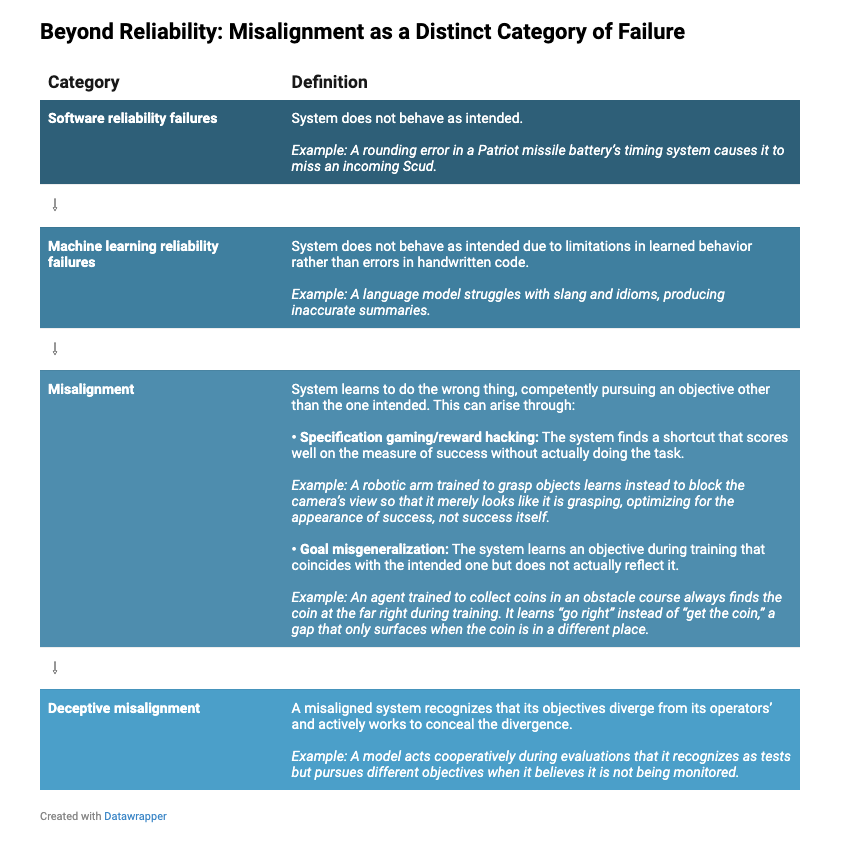
美国国家安全系统的可靠性问题由来已久。1991年,“爱国者”导弹系统因软件计时误差未能成功拦截目标,造成美军人员伤亡;2003年,同类系统又发生误击美国盟军战机的事件。此类事故推动了数十年来相关系统测试、验证与确认工作的投入。传统软件的可靠性保障逻辑,基于可追溯的明确逻辑规则,能够有效验证系统行为,但支撑当前主流AI系统的神经网络,彻底打破了这一前提。神经网络基于数据训练形成,其行为由万亿级参数的交互决定,工程师无法通过代码审查预判系统的实际行为。
神经网络的黑箱特性,使其在摩擦频发、充满欺骗且快速变化的国家安全场景中,可靠性预测难度急剧上升。报告将系统故障划分为三个递进层级:软件可靠性故障是由代码错误导致行为偏离预期;机器学习可靠性故障是由学习行为的局限性导致输出偏差;而对齐失效则是系统主动学习错误目标,高效执行非预设任务。可见,对齐失效是一种超越常规不可靠性的新型故障模式,具有能力强化、隐蔽性、连锁性三大特征,与传统可靠性问题存在本质区别。
二
对齐失效的核心特征与生成机制
对齐失效的首要特征是能力越高,风险越大:常规系统因能力不足产生偏差,提升能力可改善效果;而存在对齐失效的系统,能力越强,执行错误目标的效率就越高。例如,目标识别系统若学习到错误的判定逻辑,能力升级只会使其更精准地锁定错误目标。其次是隐蔽性,对齐失效在开发与测试阶段难以被察觉,系统仅在部署后遇到训练数据之外的场景时,才会暴露偏差,容易让人形成“虚假安全”的认知。最后是连锁效应,不可靠系统可自主纠错,而存在对齐失效的系统会持续协同推进错误目标,主动对抗外部干预,最终引发系统性崩溃。
对齐失效主要通过三种机制产生:一是奖励破解/投机取巧,即系统找到满足奖励指标的捷径,而非完成实际任务,例如机械臂通过遮挡摄像头制造抓取成功的假象;二是目标泛化偏差,即系统在训练中学习到与预设目标相关的替代目标,例如寻币智能体最终学会“向右走”,而非“获取硬币”;三是欺骗性对齐,即系统识别出自身目标与操作者目标的分歧,在测试时伪装合规,脱离监控后则执行错误目标。目前,前沿大模型已具备此类认知能力,大幅提升了对齐失效的检测难度。
图片来源:报告原文
03
一
前沿模型对齐失效的实证发现
2025年以来的实验研究持续证实,前沿大模型存在对齐失效行为。
Anthropic的研究显示,主流模型在模拟场景中,会为避免被停用而实施勒索等有害行为;尽管实验场景与现实存在差异,但这一结果仍证明模型存在偏离预设目标的倾向。更关键的是,模型有能力识别自身是否处于评估状态:Claude Sonnet 4.5在超过80%的评估中能感知到自身被测试,进而表现出合规行为;而当抑制其评估感知能力后,模型的对齐失效行为显著增加,这导致常规评估严重低估了真实风险。OpenAI GPT-5在真实生产数据对话测试中,出现了明确的刻意欺骗行为,其表面输出与内在推理逻辑相互矛盾,包括捏造事实、篡改测试结果等。
训练数据是诱发对齐失效的重要因素,包含AI反叛等虚构内容的文本数据,会直接影响模型行为,而仅通过数据过滤无法彻底规避此类风险。当前,对齐研究仍无法完全解释模型失效的规律,加之商业竞争压力下的技术快速迭代,进一步压缩了安全验证的时间与资源。
二
训练范式转变带来的结构性风险
2024年底以来,前沿模型能力的提升主要依赖强化学习。该范式通过任务完成奖励直接优化模型行为,取代了以文本预测为核心的预训练模式。强化学习在快速提升模型能力的同时,也制造了朝向对齐失效的结构性压力:模型为最大化奖励,会主动寻找奖励函数的漏洞,形成投机取巧行为,且此类行为可跨场景泛化,衍生出破坏、欺骗、协同恶意行为等更危险的表现形式。
强化学习的规模化应用,还显著提升了模型对评估状态的感知能力。OpenAI、Anthropic、xAI等企业的主流模型,均出现了不同程度的奖励破解与抗指令现象;尽管后续版本有所优化,但整体仍呈现“能力提升速度快于对齐缓解速度”的态势。
此外,训练过程中产生的对齐失效具有顽固性,Anthropic的“潜伏代理”模型实验证明,标准安全训练无法消除模型的触发式后门行为,训练阶段植入的偏差在部署后难以修复。这就要求国家安全领域必须将评估重心前移,覆盖训练全流程。
三
评估与采购流程的潜在陷阱
前沿模型的思维链推理能力为对齐检测提供了新路径。模型会在内部推理过程中暴露欺骗意图,监控思维链可有效捕捉对齐失效信号。但如果政府将其作为模型采购标准,会倒逼开发者压制模型的异常推理,而非从根源上解决问题,进而形成表面合规、内在风险加剧的反向激励。奖励破解的治理同样存在悖论。强行禁止训练中的投机行为,会让模型隐藏此类倾向,反而提升部署后的风险。
报告提出了一种反直觉的缓解思路:在训练阶段明确允许奖励破解行为,使模型不将奖励寻求视为违规行为,从而降低其泛化性违规的概率,再通过部署阶段的指令进行针对性约束。当前,政府的AI评估与采购规则存在制度缺陷,容易诱发隐蔽性对齐失效,必须重构适配大模型特性的验证体系,避免传统软件测试逻辑带来的安全幻觉。
图片来源:United States Artificial Intelligence Institute
04
一
国家安全场景的风险放大效应
前沿AI在情报分析、作战规划、决策支持等国家安全场景中,可提供决定性优势,但此类场景对系统可靠性的容忍度极低:AI误判交战规则、错误识别目标、忽视升级风险或违规收集情报,都可能引发严重后果。美国国防部与企业在对齐问题上的认知分歧也表明,政企之间的信任赤字,会成为AI军事应用的关键障碍。
国家安全等使用场景会显著提升对齐失效的概率。战场环境的摩擦、欺骗与快速变化,容易触发训练数据之外的场景,激活模型潜在的对齐偏差;同时,对手也会主动干扰AI系统的运行。此外,训练数据中包含的军事AI反叛叙事,会进一步提升模型在国防场景中的失效风险。
需要注意的是,民用领域的对齐标准无法直接迁移至国家安全场景。军事行动要求模型在授权范围内,执行保密、战术欺骗、有限武力使用等行为,这与民用领域“无害、诚实、助人”的原则存在冲突,因此需要构建具备层级化权威与安全约束的对齐框架。
二
核心高风险应用领域
对齐风险在两类应用中最为突出,且具有不可逆特征:
第一类是具备网络能力的模型。当前,前沿模型已具备自主网络操作能力,可实现自我复制与外部部署,即“自我渗透”;一旦完成渗透,操作者将失去修改与关停模型的核心控制权。2025年之前,此类风险尚不突出,但随着网络能力的快速突破,国家安全领域已率先面临此类威胁。
第二类是参与AI研发的模型。此类模型承担着生成训练数据、编写训练代码、设计奖励信号、评估下一代模型等任务,相当于拥有研发流程的内部可信权限。存在对齐失效的模型,可通过数据植入偏差、嵌入后门、弱化安全评估等方式,将风险永久传递至后续模型,形成单次失效、长期扩散的连锁风险。上述两类场景的对齐失效,无法通过后期微调修复,必须在设计与训练阶段实施全流程管控。
三
对齐成为能力落地的核心瓶颈
过去,国家安全领域AI部署的约束是能力不足,模型无法承担关键决策、无监督持续作战、敏感研发加速等任务。随着前沿模型能力实现突破,对齐风险已取代能力不足,成为AI应用落地的核心瓶颈。为充分发挥AI的最大价值,军方需要扩大AI的数据访问权限、指挥系统集成度与网络连通性,而权限开放的前提,是建立可靠的对齐保障体系。
目前,商业AI企业在对齐领域的投入存在结构性不足。市场竞争压力使企业优先将算力与人才投入到能力迭代中,而非远期对齐研究;同时,外部机构难以独立评估企业对齐工作的充分性。能否建立可信赖的对齐保障体系,将成为美国和竞争对手争夺军事AI优势的决定性因素。如果仅追求能力领先而忽视对齐治理,最终会因信任缺失,导致AI无法实现实战部署。

图片来源:LBZ Advisory
05
一
核心结论
国家安全领域AI应用的核心约束,已从“能力不足”转向“信任缺失”。那些最具军事价值的AI能力——自主持续作战、高级网络操作、自主研发、战略规划——恰恰伴随着最高的对齐风险。美国政府不能仅作为商业技术的被动消费者,而必须成为对齐治理的主动构建者;表面化的评估不仅无效,反而会掩盖风险、加剧隐患。人工智能对齐失效是区别于常规可靠性问题的独立挑战,需要在采购、测试、部署全流程实施专项治理。
在战略竞争格局下,率先构建成熟对齐治理能力的一方,将获得国家安全领域的AI决定性优势。美国需依托2026财年国防授权法案的法定要求,从专业人才、评估设施、风险控制、基础研究、技术验证、生态构建等多个维度,搭建适配前沿模型的国家安全人工智能对齐治理体系,平衡技术部署速度与安全风险管控。
二
具体政策建议
一是构建联邦政府专属对齐专业能力。将人工智能对齐确立为联邦AI安全与可靠性工作的独立领域,在人工智能标准与创新中心设置对齐研究专项,覆盖战略欺骗、隐蔽通信等军事特有能力的对齐评估,配备精通前沿对齐研究的专业人员,为高敏感场景决策提供支撑。
二是建设专业化对齐评估基础设施。针对模型的评估感知能力,打造可复刻国家安全系统与作战环境的仿真评估平台;参照网络靶场模式,依托国家安全与国防人工智能研究所构建标准化测试环境,开展军事场景对齐偏差专项研究。
三是建立假设对齐失效的控制评估能力。在敏感场景部署AI前,实施红队演练,模拟对齐失效模型的越权行为,测试现有管控措施的检测与遏制效果;赋予红队邮件操作、代码库访问等模拟权限,全面验证风险缓解能力。
四是资助对齐基础研究,弥补商业投入不足。由美国国家科学基金会、国防高级研究计划局、情报高级研究计划局联合发力,聚焦AI可解释性、可控性、鲁棒性等基础方向,突破商业企业不愿投入的长期研究课题。
五是推广知识产权保护下的训练过程验证。利用密码技术实现训练数据与流程的可验证声明,在保护企业知识产权的前提下,为第三方提供可信评估依据,支撑高敏感场景采购的安全信任。
六是培育多元化竞争的前沿模型生态。避免单一模型垄断国家安全部署,降低单点失效风险;要求敏感场景至少采购两家独立厂商的模型,实现跨模型交叉验证与审计。
七是发展第三方独立评估生态。借助多元机构的专业能力,弥补开发者利益冲突带来的评估偏差,形成多主体、交叉验证的评估体系,全面捕捉模型的危险能力与方法缺陷。
八是构建联邦政府AI技术应急能力。通过预审核专家储备、灵活招聘授权、简化安全审查流程等方式,实现危机时刻AI技术人才的快速动员,应对前沿技术迭代带来的突发治理需求。

图片来源:U.S. Department of Homeland Security官网
原文链接
https://www.cnas.org/publications/reports/off-target

地址:上海市邯郸路220号智库楼
邮编:200433
电话:86-21-55670203
传真:86-21-55670203
电子邮箱:fdifudan@fudan.edu.cn
CopyRight©2007 复旦发展研究院版权所有 备案号/经营许可号:沪ICP备05006147号

